Antoine Beaupr : Leaving Freenode
The freenode IRC network has been hijacked.
TL;DR: move to libera.chat or OFTC.net, as did countless
free software projects including Gentoo, CentOS, KDE, Wikipedia,
FOSDEM, and more. Debian and the Tor project were already on OFTC and
are not affected by this.
What is freenode and why should I care?
freenode is the largest remaining IRC network. Before this
incident, it had close to 80,000 users, which is small in terms of
modern internet history -- even small social networks are larger by
multiple orders of magnitude -- but is large in IRC history. The IRC
network is also extensively used by the free software community, being
the default IRC network on many programs, and used by hundreds if not
thousands of free software projects.
I have been using freenode since at least 2006.
This matters if you care about IRC, the internet, open protocols,
decentralisation, and, to a certain extent, federation as well. It
also touches on who has the right on network resources: the people who
"own" it (through money) or the people who make it work (through their
labor). I am biased towards open protocols, the internet, federation,
and worker power, and this might taint this analysis.
What is freenode and why should I care?
freenode is the largest remaining IRC network. Before this
incident, it had close to 80,000 users, which is small in terms of
modern internet history -- even small social networks are larger by
multiple orders of magnitude -- but is large in IRC history. The IRC
network is also extensively used by the free software community, being
the default IRC network on many programs, and used by hundreds if not
thousands of free software projects.
I have been using freenode since at least 2006.
This matters if you care about IRC, the internet, open protocols,
decentralisation, and, to a certain extent, federation as well. It
also touches on who has the right on network resources: the people who
"own" it (through money) or the people who make it work (through their
labor). I am biased towards open protocols, the internet, federation,
and worker power, and this might taint this analysis.
What happened?
It's a long story, but basically:
- back in 2017, the former head of staff sold the freenode.net
domain (and its related company) to Andrew Lee, "American
entrepreneur, software developer and writer", and, rather weirdly,
supposedly "crown prince of Korea" although that part is kind of
complex (see House of Yi, Yi Won, and Yi Seok). It
should be noted the Korean Empire hasn't existed for over a
century at this point (even though its flag, also weirdly,
remains)
- back then, this was only known to the public as this strange PIA
and freenode joining forces gimmick. it was suspicious at
first, but since the network kept running, no one paid much
attention to it. opers of the network were similarly reassured
that Lee would have no say in the management of the network
- this all changed recently when Lee asserted ownership of the
freenode.net domain and started meddling in the operations of the
network, according to this summary. this part is disputed,
but it is corroborated by almost a dozen former staff which
collectively resigned from the network in protest, after legal
threats, when it was obvious freenode was lost.
- the departing freenode staff founded a new network,
irc.libera.chat, based on the new ircd they were working on
with OFTC, solanum
- meanwhile, bot armies started attacking all IRC networks: both
libera and freenode, but also OFTC and unrelated networks like a
small one I help operate. those attacks have mostly stopped as of
this writing (2021-05-24 17:30UTC)
- on freenode, however, things are going for the worse: Lee has been
accused of taking over a channel, in a grotesque abuse of
power; then changing freenode policy to not only justify the
abuse, but also remove rules against hateful speech, effectively
allowing nazis on the network (update: the change was
reverted, but not by Lee)
Update: even though the policy change was reverted, the actual
conversations allowed on freenode have already degenerated into toxic
garbage. There are also massive channel takeovers (presumably
over 700), mostly on channels that were redirecting to libera,
but also channels that were still live. Channels that were taken
over include #fosdem, #wikipedia, #haskell...
Instead of working on the network, the new "so-called freenode" staff
is spending effort writing bots and patches to basically automate
taking over channels. I run an IRC network and this bot is
obviously not standard "services" stuff... This is just grotesque.
At this point I agree with this HN comment:
We should stop implicitly legitimizing Andrew Lee's power grab by
referring to his dominion as "Freenode". Freenode is a
quarter-century-old community that has changed its name to
libera.chat; the thing being referred to here as "Freenode" is
something else that has illegitimately acquired control of
Freenode's old servers and user database, causing enormous
inconvenience to the real Freenode.
I don't agree with the suggested name there, let's instead call it "so
called freenode" as suggested later in the thread.
What now?
I recommend people and organisations move away from freenode as soon
as possible. This is a major change: documentation needs to be fixed,
and the migration needs to be coordinated. But I do not believe we can
trust the new freenode "owners" to operate the network reliably and in
good faith.
It's also important to use the current momentum to build a critical
mass elsewhere so that people don't end up on freenode again by
default and find an even more toxic community than your typical
run-of-the-mill free software project (which is already not a high bar
to meet).
Update: people are moving to libera in droves. It's now reaching
18,000 users, which is bigger than OFTC and getting close to the
largest, traditionnal, IRC networks (EFnet, Undernet, IRCnet are in
the 10-20k users range). so-called freenode is still larger, currently
clocking 68,000 users, but that's a huge drop from the previous count
which was 78,000 before the exodus began. We're even starting to see
the effects of the migration on netsplit.de.
Update 2: the isfreenodedeadyet.com site is updated more
frequently than netsplit and shows tons more information. It shows 25k
online users for libera and 61k for so-called freenode (down from
~78k), and the trend doesn't seem to be stopping for so-called
freenode. There's also a list of 400+ channels that have moved
out. Keep in mind that such migrations take effect over long
periods of time.
Where do I move to?
The first thing you should do is to figure out which tool to use for
interactive user support. There are multiple alternatives, of course
-- this is the internet after all -- but here is a short list of
suggestions, in preferred priority order:
- irc.libera.chat
- irc.OFTC.net
- Matrix.org, which bridges with OFTC and (hopefully soon) with
libera as well, modern IRC alternative
- XMPP/Jabber also still exists, if you're into that kind of
stuff, but I don't think the "chat room" story is great there, at
least not as good as Matrix
Basically, the decision tree is this:
- if you want to stay on IRC:
- if you are already on many OFTC channels and few freenode
channels: move to OFTC
- if you are more inclined to support the previous freenode staff:
move to libera
- if you care about matrix users (in the short term): move to
OFTC
- if you are ready to leave IRC:
- if you want the latest and greatest: move to Matrix
- if you like XML and already use XMPP: move to XMPP
Frankly, at this point, everyone should seriously consider moving to
Matrix. The user story is great, the web is a first class user, it
supports E2EE (although XMPP as well), and has a lot of momentum
behind it. It even bridges with IRC well (which is not the case for
XMPP) so if you're worried about problems like this happening again.
(Indeed, I wouldn't be surprised if similar drama happens on OFTC or
libera in the future. The history of IRC is full of such epic
controversies, takeovers, sabotage, attacks, technical flamewars, and
other silly things. I am not sure, but I suspect a federated model
like Matrix might be more resilient to conflicts like this one.)
Changing protocols might mean losing a bunch of users however: not
everyone is ready to move to Matrix, for example. Graybeards like me
have been using irssi for years, if not decades, and would take quite
a bit of convincing to move elsewhere.
I have mostly kept my channels on IRC, and moved either to OFTC or
libera. In retrospect, I think I might have moved everything to OFTC
if I would have thought about it more, because almost all of my
channels are there. But I kind of expect a lot of the freenode
community to move to libera, so I am keeping a socket open there
anyways.
How do I move?
The first thing you should do is to update documentation, websites,
and source code to stop pointing at freenode altogether. This is what
I did for feed2exec, for example. You need to let people know in
the current channel as well, and possibly shutdown the channel on
freenode.
Since my channels are either small or empty, I took the radical
approach of:
- redirecting the channel to
##unavailable which is historically
the way we show channels have moved to another network
- make the channel invite-only (which effectively enforces the
redirection)
- kicking everyone out of the channel
- kickban people who rejoin
- set the topic to announce the change
In IRC speak, the following commands should do all this:
/msg ChanServ set #anarcat mlock +if ##unavailable
/msg ChanServ clear #anarcat users moving to irc.libera.chat
/msg ChanServ set #anarcat restricted on
/topic #anarcat this channel has moved to irc.libera.chat
If the channel is not registered, the following might work
/mode #anarcat +if ##unavailable
Then you can leave freenode altogether:
/disconnect Freenode unacceptable hijack, policy changes and takeovers. so long and thanks for all the fish.
Keep in mind that some people have been unable to setup such
redirections, because the new freenode staff have taken over their
channel, in which case you're out of luck...
Some people have expressed concern about their private data hosted at
freenode as well. If you care about this, you can always talk to
NickServ and DROP your nick. Be warned, however, that this assumes
good faith of the network operators, which, at this point, is kind of
futile. I would assume any data you have registered on there
(typically: your NickServ password and email address) to be
compromised and leaked. If your password is used elsewhere (tsk, tsk),
change it everywhere.
Update: there's also another procedure, similar to the above, but
with a different approach. Keep in mind that so-called freenode staff
are actively hijacking channels for the mere act of mentioning libera
in the channel topic, so thread carefully there.
Last words
This is a sad time for IRC in general, and freenode in
particular. It's a real shame that the previous freenode staff have
been kicked out, and it's especially horrible that if the new policies of
the network are basically making the network open to nazis. I wish
things would have gone out differently: now we have yet another fork
in the IRC history. While it's not the first time freenode changes
name (it was called OPN before), now the old freenode is still around
and this will bring much confusion to the world, especially since the
new freenode staff is still claiming to support FOSS.
I understand there are many sides to this story, and some people were
deeply hurt by all this. But for me, it's completely unacceptable
to keep pushing your staff so hard that they basically all (except
one?) resign in protest. For me, that's leadership failure at the
utmost, and a complete disgrace. And of course, I can't in good
conscience support or join a network that allows hate speech.
Regardless of the fate of whatever we'll call what's left of freenode,
maybe it's time for this old IRC thing to die already. It's still a
sad day in internet history, but then again, maybe IRC will never
die...
- back in 2017, the former head of staff sold the freenode.net domain (and its related company) to Andrew Lee, "American entrepreneur, software developer and writer", and, rather weirdly, supposedly "crown prince of Korea" although that part is kind of complex (see House of Yi, Yi Won, and Yi Seok). It should be noted the Korean Empire hasn't existed for over a century at this point (even though its flag, also weirdly, remains)
- back then, this was only known to the public as this strange PIA and freenode joining forces gimmick. it was suspicious at first, but since the network kept running, no one paid much attention to it. opers of the network were similarly reassured that Lee would have no say in the management of the network
- this all changed recently when Lee asserted ownership of the freenode.net domain and started meddling in the operations of the network, according to this summary. this part is disputed, but it is corroborated by almost a dozen former staff which collectively resigned from the network in protest, after legal threats, when it was obvious freenode was lost.
- the departing freenode staff founded a new network, irc.libera.chat, based on the new ircd they were working on with OFTC, solanum
- meanwhile, bot armies started attacking all IRC networks: both libera and freenode, but also OFTC and unrelated networks like a small one I help operate. those attacks have mostly stopped as of this writing (2021-05-24 17:30UTC)
- on freenode, however, things are going for the worse: Lee has been accused of taking over a channel, in a grotesque abuse of power; then changing freenode policy to not only justify the abuse, but also remove rules against hateful speech, effectively allowing nazis on the network (update: the change was reverted, but not by Lee)
We should stop implicitly legitimizing Andrew Lee's power grab by referring to his dominion as "Freenode". Freenode is a quarter-century-old community that has changed its name to libera.chat; the thing being referred to here as "Freenode" is something else that has illegitimately acquired control of Freenode's old servers and user database, causing enormous inconvenience to the real Freenode.I don't agree with the suggested name there, let's instead call it "so called freenode" as suggested later in the thread.
What now?
I recommend people and organisations move away from freenode as soon
as possible. This is a major change: documentation needs to be fixed,
and the migration needs to be coordinated. But I do not believe we can
trust the new freenode "owners" to operate the network reliably and in
good faith.
It's also important to use the current momentum to build a critical
mass elsewhere so that people don't end up on freenode again by
default and find an even more toxic community than your typical
run-of-the-mill free software project (which is already not a high bar
to meet).
Update: people are moving to libera in droves. It's now reaching
18,000 users, which is bigger than OFTC and getting close to the
largest, traditionnal, IRC networks (EFnet, Undernet, IRCnet are in
the 10-20k users range). so-called freenode is still larger, currently
clocking 68,000 users, but that's a huge drop from the previous count
which was 78,000 before the exodus began. We're even starting to see
the effects of the migration on netsplit.de.
Update 2: the isfreenodedeadyet.com site is updated more
frequently than netsplit and shows tons more information. It shows 25k
online users for libera and 61k for so-called freenode (down from
~78k), and the trend doesn't seem to be stopping for so-called
freenode. There's also a list of 400+ channels that have moved
out. Keep in mind that such migrations take effect over long
periods of time.
Where do I move to?
The first thing you should do is to figure out which tool to use for
interactive user support. There are multiple alternatives, of course
-- this is the internet after all -- but here is a short list of
suggestions, in preferred priority order:
- irc.libera.chat
- irc.OFTC.net
- Matrix.org, which bridges with OFTC and (hopefully soon) with
libera as well, modern IRC alternative
- XMPP/Jabber also still exists, if you're into that kind of
stuff, but I don't think the "chat room" story is great there, at
least not as good as Matrix
Basically, the decision tree is this:
- if you want to stay on IRC:
- if you are already on many OFTC channels and few freenode
channels: move to OFTC
- if you are more inclined to support the previous freenode staff:
move to libera
- if you care about matrix users (in the short term): move to
OFTC
- if you are ready to leave IRC:
- if you want the latest and greatest: move to Matrix
- if you like XML and already use XMPP: move to XMPP
Frankly, at this point, everyone should seriously consider moving to
Matrix. The user story is great, the web is a first class user, it
supports E2EE (although XMPP as well), and has a lot of momentum
behind it. It even bridges with IRC well (which is not the case for
XMPP) so if you're worried about problems like this happening again.
(Indeed, I wouldn't be surprised if similar drama happens on OFTC or
libera in the future. The history of IRC is full of such epic
controversies, takeovers, sabotage, attacks, technical flamewars, and
other silly things. I am not sure, but I suspect a federated model
like Matrix might be more resilient to conflicts like this one.)
Changing protocols might mean losing a bunch of users however: not
everyone is ready to move to Matrix, for example. Graybeards like me
have been using irssi for years, if not decades, and would take quite
a bit of convincing to move elsewhere.
I have mostly kept my channels on IRC, and moved either to OFTC or
libera. In retrospect, I think I might have moved everything to OFTC
if I would have thought about it more, because almost all of my
channels are there. But I kind of expect a lot of the freenode
community to move to libera, so I am keeping a socket open there
anyways.
How do I move?
The first thing you should do is to update documentation, websites,
and source code to stop pointing at freenode altogether. This is what
I did for feed2exec, for example. You need to let people know in
the current channel as well, and possibly shutdown the channel on
freenode.
Since my channels are either small or empty, I took the radical
approach of:
- redirecting the channel to
##unavailable which is historically
the way we show channels have moved to another network
- make the channel invite-only (which effectively enforces the
redirection)
- kicking everyone out of the channel
- kickban people who rejoin
- set the topic to announce the change
In IRC speak, the following commands should do all this:
/msg ChanServ set #anarcat mlock +if ##unavailable
/msg ChanServ clear #anarcat users moving to irc.libera.chat
/msg ChanServ set #anarcat restricted on
/topic #anarcat this channel has moved to irc.libera.chat
If the channel is not registered, the following might work
/mode #anarcat +if ##unavailable
Then you can leave freenode altogether:
/disconnect Freenode unacceptable hijack, policy changes and takeovers. so long and thanks for all the fish.
Keep in mind that some people have been unable to setup such
redirections, because the new freenode staff have taken over their
channel, in which case you're out of luck...
Some people have expressed concern about their private data hosted at
freenode as well. If you care about this, you can always talk to
NickServ and DROP your nick. Be warned, however, that this assumes
good faith of the network operators, which, at this point, is kind of
futile. I would assume any data you have registered on there
(typically: your NickServ password and email address) to be
compromised and leaked. If your password is used elsewhere (tsk, tsk),
change it everywhere.
Update: there's also another procedure, similar to the above, but
with a different approach. Keep in mind that so-called freenode staff
are actively hijacking channels for the mere act of mentioning libera
in the channel topic, so thread carefully there.
Last words
This is a sad time for IRC in general, and freenode in
particular. It's a real shame that the previous freenode staff have
been kicked out, and it's especially horrible that if the new policies of
the network are basically making the network open to nazis. I wish
things would have gone out differently: now we have yet another fork
in the IRC history. While it's not the first time freenode changes
name (it was called OPN before), now the old freenode is still around
and this will bring much confusion to the world, especially since the
new freenode staff is still claiming to support FOSS.
I understand there are many sides to this story, and some people were
deeply hurt by all this. But for me, it's completely unacceptable
to keep pushing your staff so hard that they basically all (except
one?) resign in protest. For me, that's leadership failure at the
utmost, and a complete disgrace. And of course, I can't in good
conscience support or join a network that allows hate speech.
Regardless of the fate of whatever we'll call what's left of freenode,
maybe it's time for this old IRC thing to die already. It's still a
sad day in internet history, but then again, maybe IRC will never
die...
- irc.libera.chat
- irc.OFTC.net
- Matrix.org, which bridges with OFTC and (hopefully soon) with libera as well, modern IRC alternative
- XMPP/Jabber also still exists, if you're into that kind of stuff, but I don't think the "chat room" story is great there, at least not as good as Matrix
- if you want to stay on IRC:
- if you are already on many OFTC channels and few freenode channels: move to OFTC
- if you are more inclined to support the previous freenode staff: move to libera
- if you care about matrix users (in the short term): move to OFTC
- if you are ready to leave IRC:
- if you want the latest and greatest: move to Matrix
- if you like XML and already use XMPP: move to XMPP
How do I move?
The first thing you should do is to update documentation, websites,
and source code to stop pointing at freenode altogether. This is what
I did for feed2exec, for example. You need to let people know in
the current channel as well, and possibly shutdown the channel on
freenode.
Since my channels are either small or empty, I took the radical
approach of:
- redirecting the channel to
##unavailable which is historically
the way we show channels have moved to another network
- make the channel invite-only (which effectively enforces the
redirection)
- kicking everyone out of the channel
- kickban people who rejoin
- set the topic to announce the change
In IRC speak, the following commands should do all this:
/msg ChanServ set #anarcat mlock +if ##unavailable
/msg ChanServ clear #anarcat users moving to irc.libera.chat
/msg ChanServ set #anarcat restricted on
/topic #anarcat this channel has moved to irc.libera.chat
If the channel is not registered, the following might work
/mode #anarcat +if ##unavailable
Then you can leave freenode altogether:
/disconnect Freenode unacceptable hijack, policy changes and takeovers. so long and thanks for all the fish.
Keep in mind that some people have been unable to setup such
redirections, because the new freenode staff have taken over their
channel, in which case you're out of luck...
Some people have expressed concern about their private data hosted at
freenode as well. If you care about this, you can always talk to
NickServ and DROP your nick. Be warned, however, that this assumes
good faith of the network operators, which, at this point, is kind of
futile. I would assume any data you have registered on there
(typically: your NickServ password and email address) to be
compromised and leaked. If your password is used elsewhere (tsk, tsk),
change it everywhere.
Update: there's also another procedure, similar to the above, but
with a different approach. Keep in mind that so-called freenode staff
are actively hijacking channels for the mere act of mentioning libera
in the channel topic, so thread carefully there.
Last words
This is a sad time for IRC in general, and freenode in
particular. It's a real shame that the previous freenode staff have
been kicked out, and it's especially horrible that if the new policies of
the network are basically making the network open to nazis. I wish
things would have gone out differently: now we have yet another fork
in the IRC history. While it's not the first time freenode changes
name (it was called OPN before), now the old freenode is still around
and this will bring much confusion to the world, especially since the
new freenode staff is still claiming to support FOSS.
I understand there are many sides to this story, and some people were
deeply hurt by all this. But for me, it's completely unacceptable
to keep pushing your staff so hard that they basically all (except
one?) resign in protest. For me, that's leadership failure at the
utmost, and a complete disgrace. And of course, I can't in good
conscience support or join a network that allows hate speech.
Regardless of the fate of whatever we'll call what's left of freenode,
maybe it's time for this old IRC thing to die already. It's still a
sad day in internet history, but then again, maybe IRC will never
die...
##unavailable which is historically
the way we show channels have moved to another network/msg ChanServ set #anarcat mlock +if ##unavailable
/msg ChanServ clear #anarcat users moving to irc.libera.chat
/msg ChanServ set #anarcat restricted on
/topic #anarcat this channel has moved to irc.libera.chat
/mode #anarcat +if ##unavailable
/disconnect Freenode unacceptable hijack, policy changes and takeovers. so long and thanks for all the fish.



 fully assembled chromebook duet
fully assembled chromebook duet
 ...even the SD cards were wet!
...even the SD cards were wet!
 The last photo my camera took before it died
The last photo my camera took before it died
 Tada! Turns out you can dehydrate hardware too!
Tada! Turns out you can dehydrate hardware too!
 A good six years ago I
A good six years ago I 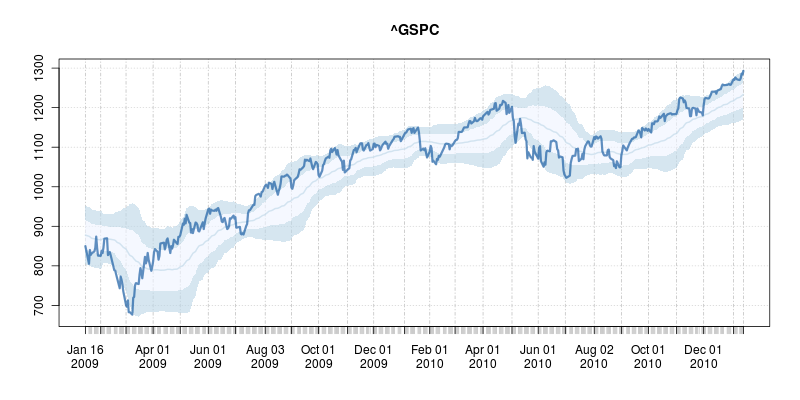 The code uses a few standard finance packages for R (with most of them maintained by
The code uses a few standard finance packages for R (with most of them maintained by 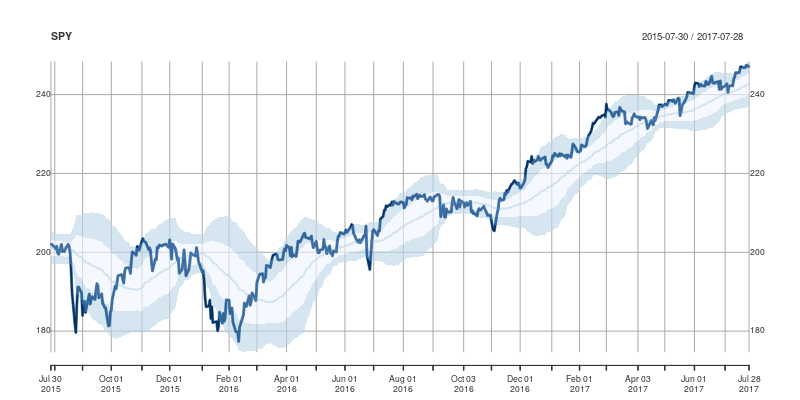 Comments and further enhancements welcome!
Comments and further enhancements welcome!
 Yesterday I uploaded the first packages of
Yesterday I uploaded the first packages of  I mentioned already in a
I mentioned already in a 
 I release them under the
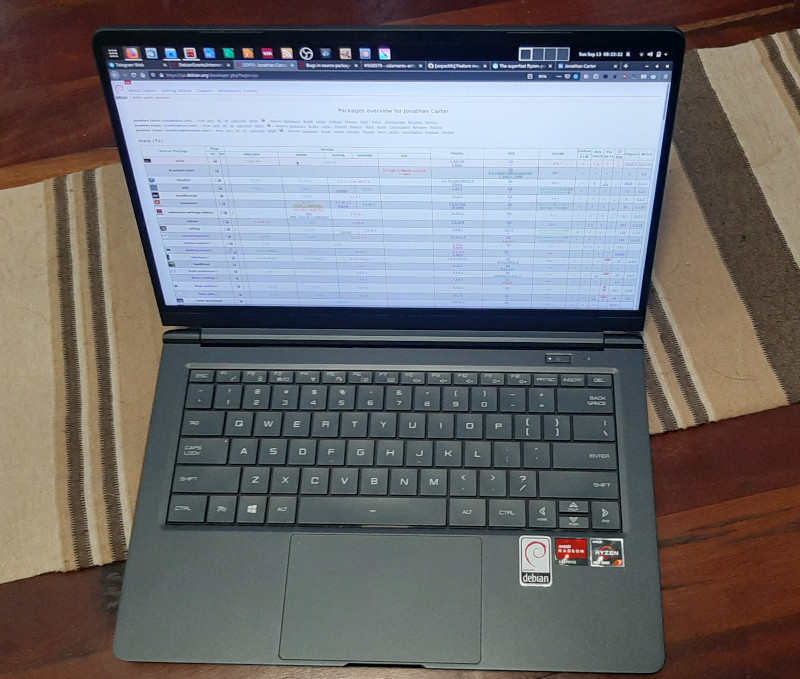
I release them under the  Here is my monthly update covering what I have been doing in the free software world (
Here is my monthly update covering what I have been doing in the free software world ( Dear lazyweb,
I am trying to get a good way to present the categorization of several cases studied with a fitting graph. I am rating several vulnerabilities / failures according to James Cebula et. al.'s paper,
Dear lazyweb,
I am trying to get a good way to present the categorization of several cases studied with a fitting graph. I am rating several vulnerabilities / failures according to James Cebula et. al.'s paper, 



 These days, most large FLOSS communities have a "Code of Conduct"; a
document that outlines the acceptable (and possibly not acceptable)
behaviour that contributors to the community should or should not
exhibit. By writing such a document, a community can arm itself more
strongly in the fight against trolls, harassment, and other forms of
antisocial behaviour that is rampant on the anonymous medium that the
Internet still is.
Writing a good code of conduct is no easy matter, however. I should know
-- I've been involved in such a process twice; once for
These days, most large FLOSS communities have a "Code of Conduct"; a
document that outlines the acceptable (and possibly not acceptable)
behaviour that contributors to the community should or should not
exhibit. By writing such a document, a community can arm itself more
strongly in the fight against trolls, harassment, and other forms of
antisocial behaviour that is rampant on the anonymous medium that the
Internet still is.
Writing a good code of conduct is no easy matter, however. I should know
-- I've been involved in such a process twice; once for
 If you write a list of things not to do, then by implication (because
you didn't mention them), the things in the gray area are okay. This is
especially problematic when it comes to things that are borderline
blacklisted behaviour (or that should be blacklisted but aren't, because
your list is incomplete -- see above). In such a situation, you're
dealing with people who are jerks but can argue about it because your
definition of jerk didn't cover teir behaviour. Because they're jerks,
you can be sure they'll do everything in their power to waste your time
about it, rather than improving their behaviour.
In contrast, if you write a list of things that you want people to do,
then by implication (because you didn't mention it), the things in the
gray area are not okay. If someone slips and does something in that
gray area anyway, then that probably means they're doing something
borderline not-whitelisted, which would be mildly annoying but doesn't
make them jerks. If you point that out to them, they might go "oh,
right, didn't think of it that way, sorry, will aspire to be better next
time". Additionally, the actual jerks and trolls will have been given
less tools to argue about borderline violations (because the border of
your code of conduct is far, far away from jerky behaviour), so less
time is wasted for those of your community who have to police it (yay!).
In theory, the result of a whitelist is a community of people who aspire
to be nice people, rather than a community of people who simply aspire
to be "not jerks". I know which kind of community I prefer.
If you write a list of things not to do, then by implication (because
you didn't mention them), the things in the gray area are okay. This is
especially problematic when it comes to things that are borderline
blacklisted behaviour (or that should be blacklisted but aren't, because
your list is incomplete -- see above). In such a situation, you're
dealing with people who are jerks but can argue about it because your
definition of jerk didn't cover teir behaviour. Because they're jerks,
you can be sure they'll do everything in their power to waste your time
about it, rather than improving their behaviour.
In contrast, if you write a list of things that you want people to do,
then by implication (because you didn't mention it), the things in the
gray area are not okay. If someone slips and does something in that
gray area anyway, then that probably means they're doing something
borderline not-whitelisted, which would be mildly annoying but doesn't
make them jerks. If you point that out to them, they might go "oh,
right, didn't think of it that way, sorry, will aspire to be better next
time". Additionally, the actual jerks and trolls will have been given
less tools to argue about borderline violations (because the border of
your code of conduct is far, far away from jerky behaviour), so less
time is wasted for those of your community who have to police it (yay!).
In theory, the result of a whitelist is a community of people who aspire
to be nice people, rather than a community of people who simply aspire
to be "not jerks". I know which kind of community I prefer.
 If you take a random computer today, it's pretty much a given that it runs
a 24-bit mode (8 bits of each of R, G and B); as we moved from palettized
displays at some point during the 90s, we quickly went past 15- and 16-bit and
settled on 24-bit. The reasons are simple; 8 bits per channel is easy to work
with on CPUs, and it's on the verge of what human vision can distinguish,
at least if you add some dither. As we've been slowly taking the CPU off the
pixel path and replacing it with GPUs (which has specialized hardware for
more kinds of pixels formats), changing formats have become easier, and
there's some push to 10-bit (30-bit) deep color for photo pros, but largely,
8-bit per channel is where we are.
Yet, I'm now spending time adding 10-bit input (and eventually also 10-bit
output) to
If you take a random computer today, it's pretty much a given that it runs
a 24-bit mode (8 bits of each of R, G and B); as we moved from palettized
displays at some point during the 90s, we quickly went past 15- and 16-bit and
settled on 24-bit. The reasons are simple; 8 bits per channel is easy to work
with on CPUs, and it's on the verge of what human vision can distinguish,
at least if you add some dither. As we've been slowly taking the CPU off the
pixel path and replacing it with GPUs (which has specialized hardware for
more kinds of pixels formats), changing formats have become easier, and
there's some push to 10-bit (30-bit) deep color for photo pros, but largely,
8-bit per channel is where we are.
Yet, I'm now spending time adding 10-bit input (and eventually also 10-bit
output) to  In several of my
In several of my 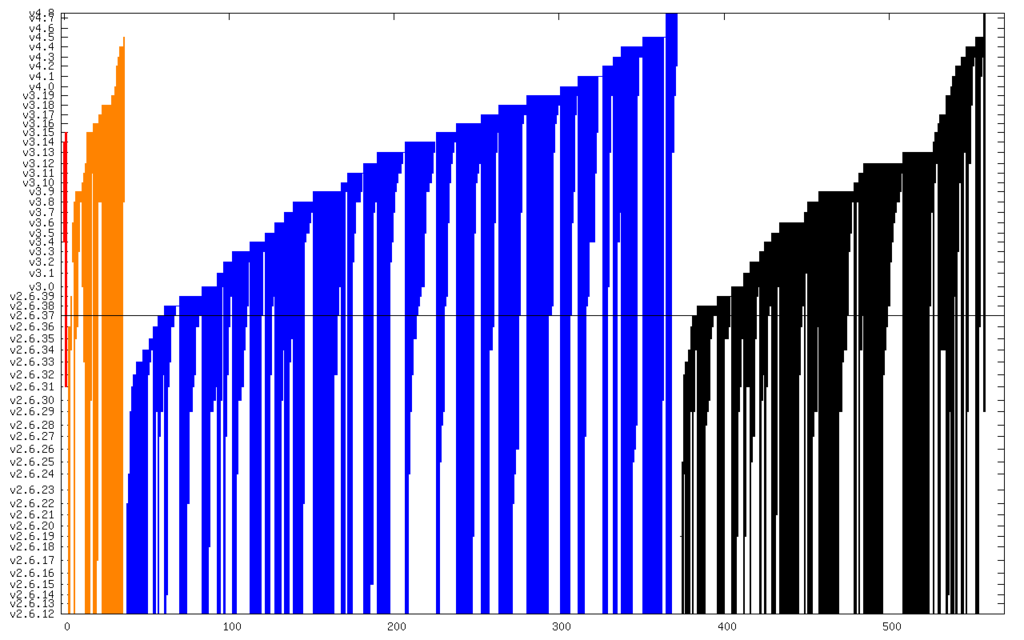 And here it is zoomed in to just Critical and High:
And here it is zoomed in to just Critical and High:
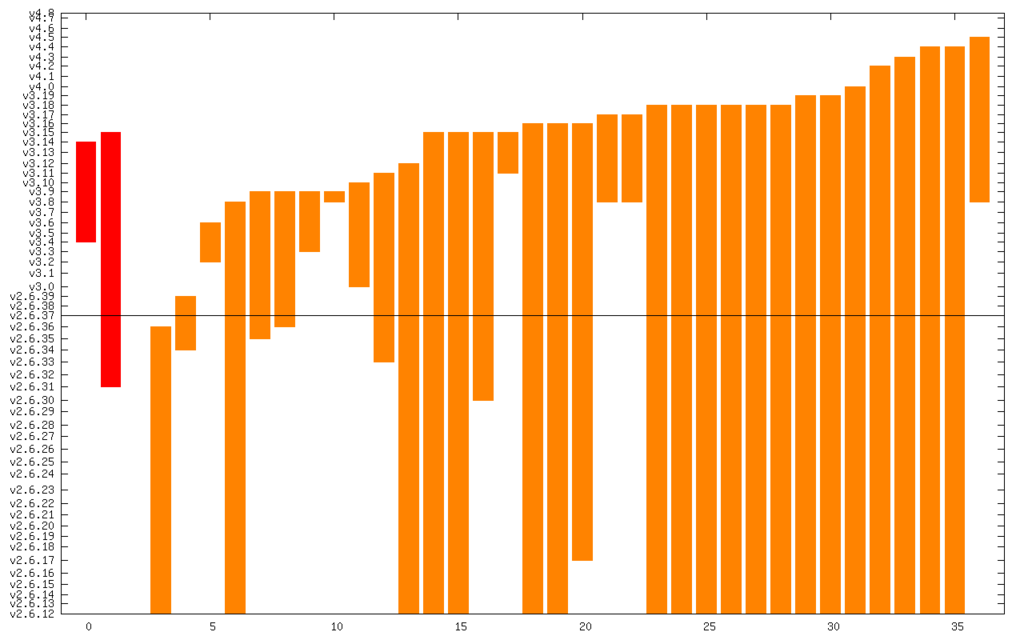 The line in the middle is the date from which I started the CVE search (2011). The vertical axis is actually linear time, but it s labeled with kernel releases (which are pretty regular). The numerical summary is:
The line in the middle is the date from which I started the CVE search (2011). The vertical axis is actually linear time, but it s labeled with kernel releases (which are pretty regular). The numerical summary is:

{kind=link}
{kind=link}